
AI是星辰大海,中国AI在「算法」与「算力」领域呈现双子星闪耀的新格局。 2025年开春以来,中国「AI群星」璀璨,它们以「低成本高效率」的方式创新,让大洋彼岸的硅谷为之震惊。 1月20日,Deep...
手机扫码免费下载
纠错留言#国产AI双子星闪耀简介
AI是星辰大海,中国AI在「算法」与「算力」领域呈现双子星闪耀的新格局。
2025年开春以来,中国「AI群星」璀璨,它们以「低成本高效率」的方式创新,让大洋彼岸的硅谷为之震惊。
1月20日,DeepSeek-R1模型系列横空出世,它仅用OpenAI不到十分之一的成本,就达到了后者最新大模型的优越性能。
DeepSeek的颠覆性创新与极致的效率革命,让硅谷一众大佬为之惊诧。几乎一夜之间,微软、英伟达、亚马逊全部接入DeepSeek。
就连全球大模型龙头公司OpenAI首席执行官奥特曼也不得不承认:「我们错了!DeepSeek让OpenAI优势不再。」
1月28日,宇树科技的人形机器人亮相春晚,16个人形机器人身着秧歌服,灵活的机械臂挥舞手帕,它们的表现同样惊艳全球。
专业人士对比官方视频发现,宇树科技比马斯克旗下的Optimus更灵活稳定强大,其背后有中国「优质高效低价」的产业链支撑。
前几天,国内首个自研万卡集群百度智能云正式点亮,它点亮了昆仑芯三代万卡集群,推动模型降本指数级下降趋势。
花旗银行发布研报惊呼,DeepSeek、百度等中国模型展现出高效和低成本优势,将有助于加速全球AI应用开发,并在全球引发更多技术创新,推动2025年人工智能应用的拐点。
DeepSeek进化「算法」,百度云推动「算力」降本增效。
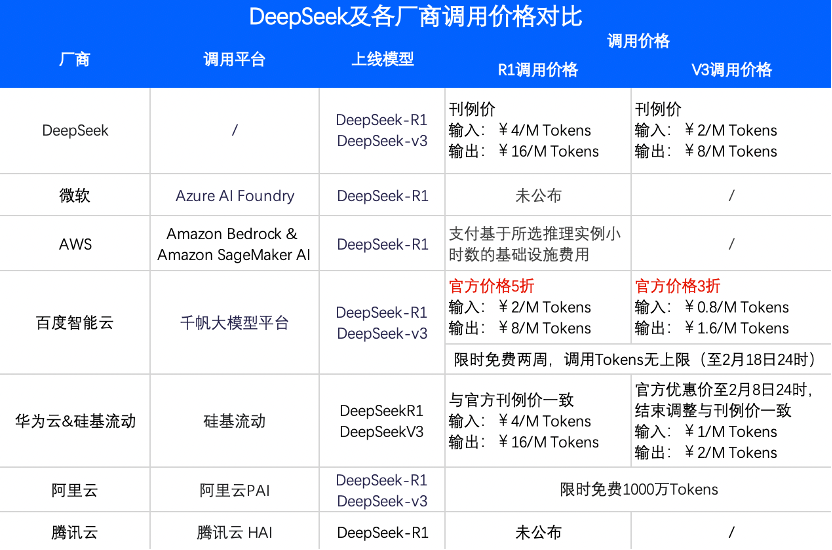
值得关注的是,百度与DeepSeek牵手合作,继续降本。2月3日,DeepSeek-R1及DeepSeek-V3两款大模型已上架百度智能云旗下ModelBuilder平台,价格仅为DeepSeek-V3官方刊例价的3折,DeepSeek-R1官方刊例价的5折,并提供限时免费服务。
AI是星辰大海,中国AI在「算法」与「算力」呈现双子星闪耀的新格局。
1|花小钱办大事:中国科技公司刮起「降本风」
目前人工智能之所以无法大规模落地,最主要的原因是算力成本过高。
芯片遵守摩尔定律 ,AGI(通用人工智能)则遵从Scaling Law(模型规模定律)。
Scaling Law被认为是大模型训练的「第一性原理」,模型性能与规模(参数量、数据大小、算力资源)呈正相关——参数越多、计算资源越大,模型的性能就越强。
简言之,模型「算法」与「算力」是大模型进化最重要的两个因子。
硅谷科技巨头都在疯狂筹备「算力」扩张,并伴随着巨额资金。
据统计,苹果、微软、谷歌、亚马逊、Meta五巨头在AI赛道的资本开支超过2200亿美元,2025年有望继续增长19.6%。其中,微软计划在2025财年砸下800亿美元,用于建设人工智能数据中心。
前不久,美国政府联合OpenAI、甲骨文、软银等启动「星际之门」项目,计划在未来四年内最高投资5000亿美元。
如今全球AI行业都在讨论算力,本质上都只有一个目的:把算力成本降下来,才能在产业应用中实现量变达成质变的生产力变革。
大模型每一次计算都要消耗一波算力,这个成本是无法忽略的。据研报披露,谷歌每次搜索的成本大约是2美分,如果将搜索改为大语言模型的问答,单次反馈的成本将至少是普通搜索的7倍。
没有算力成本的充分下降,AI大规模赋能产业就是一个伪命题。把算力成本降下来,才能在产业应用中实现量变达成质变的生产力变革。中小企业无法承担大模型算力带来的高成本。
正如前文所述,DeepSeek颠覆了固有的「大力出奇迹」的大模型「算法」提升路径。
在算力上,用「花小钱办大事」的方式,中国找到了新方案——国内首个自研万卡集群百度智能云,它实现了算力翻倍提升,成本大幅度降低。
百度通过自研芯片和大规模集群的建设,不仅解决了自身算力供应的问题,还为整个行业提供了新的思路和方向。
从算力上看,其超大规模并行计算能力可实现训练效率跃升,万卡集群可将千亿参数模型的训练周期大幅降低,满足AI原生应用快速迭代的需求。
同时也能支持更大模型与复杂任务和多模态数据,支撑Sora类应用的开发。
此外,万卡集群能够支持多任务并发能力,通过动态资源切分,单集群可同时训练多个轻量化模型,通过通信优化与容错机制减少算力浪费,实现训练成本指数级下降。
依托百度百舸高效、稳定、混合多芯的能力,生数科技得以在短时间内完成了Vidu的上线和开放API。Vidu训练效率大幅提升,其素材渲染加速效率提升3倍,数据拉取效率提升51倍。
长安汽车通过与百度智能云的深度合作,基于百度百舸4.0,达到了算力总体平均使用率提升到90%以上的显著效果。
2|万卡集群:重塑算力产业
算力是一个系统性工程,中国科技公司以创新的方式破解算力难题。
算力是什么?
很多人单纯认为就是芯片。所以2024年,全球芯片公司暴涨,英伟达成为全球市值最高的公司。
硅谷的大模型公司,一直在强调购买英伟达芯片的数量。但这只是资本市场有目的的助推误区。
AI大模型强调落地应用,支撑大模型的算力也同理。
从硬件到软件,到算法调度,到接入数据,到产业应用,整个算力产业是一个复杂而系统的综合工程。每一个环节的成本、效率、耗能,都会直接影响算力的最终实际输出结果。
如今,中国算力市场出现了新格局:
其一,以移动、电信、联通为代表的三大运营商,它们承接全国算力网一体化。
其二,百度云、阿里云、腾讯云、华为云等为代表的科技大厂,它们在大模型产业链上的芯片、大模型研发产品、运营等方面全面布局,更在「降本增效」上创新。
各大算力主体各有优势,并相互交融。
而百度通过「降本增效」重塑算力——万卡集群「新范式」。
什么是万卡集群?
简单来说,万卡集群是指由超过一万张加速卡(例如GPU、TPU等)组成的高性能计算系统。这一系统不仅提升了人工智能模型的训练速度,也大幅提高了推理效率。
过去,多芯混训和激增的故障率等难题,成为万卡集群部署过程中的巨大挑战。
去年9月,百度升级AI异构计算平台4.0——百舸平台,它在万卡集群的建设中发挥了关键作用:
其一,突破硬件扩展性瓶颈,如卡间互联的拓扑限制,避免通信带宽成为瓶颈;
其二,围绕芯片及集群功耗,基于万卡规模常规方案功耗可达十兆瓦或更高,采用创新性散热方案,从而解决万卡集群的能效与散热问题;完善模型的分布式训练优化,采用高效并行化任务切分策略,训练主流开源模型的集群MFU提升至58%;
在提升稳定性方面,提供容错与稳定性机制,避免由于单卡故障率随规模指数上升而造成的万卡集群有效性大幅下降,保障有效训练率达到98%;
其三,针对机间通信带宽需求,建设超大规模HPN高性能网络,优化拓扑结构,从而降低通信瓶颈,带宽有效性达到90%以上。
百舸4.0构建了十万卡级别的超大规模HPN高性能网络,针对跨地域通信中的高延迟问题,通过优化的拓扑结构、多路径负载均衡策略及通信策略,实现了几十公里的跨地域通信。
在通信效率上,百舸通过先进的拥塞控制算法和集合通信算法策略,实现完全无阻塞,并通过10ms级别超高精度网络监控,保障网络稳定性。
在多芯混训方面,百舸展现出强大的资源整合能力。它能够将不同地点、不同规模的异构算力进行统一管理,构建起多芯资源池。
当业务提交工作负载时,百舸可自动进行芯片选型,依据集群剩余的芯片资源,选择性价比最高的芯片来运行任务,从而最大化地利用集群的剩余资源,实现高达95%的万卡多芯混合训练效能。
此外,在集群稳定性方面,百舸提供了全面的故障诊断手段,能够快速自动侦测到导致训练任务异常的节点故障。百度自研的BCCL(百度集合通信库)能够快速定位故障并提供自动化的容错能力,将故障恢复时间从小时级降低到分钟级,极大地提高了集群的可靠性和可用性。
中国工程院院士、清华大学计算机系教授郑纬民直言,当下构建国产自主万卡系统充满挑战,但「至关重要」。
未来的大模型所需的算力预计还会呈指数级增长,如同一个工人埋头苦干与一万工人分工合作,其效率无法同日而语。
3|中国AI创新:算力新引擎
如今,人工智能与科技走到了拐点,算力决定了拐点的倾斜度与速度。
纵观过去三次科技革命:
第一次工业革命,核心驱动力是马力,它帮助人类在纺织、交通等行业解放了生产力。
第二次电力革命,核心驱动力是电,它让钢铁等产业爆发式增长。
第三次互联网革命,核心驱动力是信息传输能力,从3G到5G,从互联网到移动互联网。
这次人工智能革命,其核心驱动力是算法和算力。
2025年,全球科技巨头蓄势待发。
根据《中国综合算力指数(2024年)》报告,截至2023年末,我国算力基础设施规模占全球的26%,名列第二。而到了2025年,我国算力规模将达到300EFLOPS,智能算力占比要达到35%。
中国AI在「算法」与「算力」两个领域同时创新,并同样以「花小钱办大事」的方式实现了对算力的「降本增效」。
为什么DeepSeek、百度走在了前列?
毫无疑问,一方面,是源于中国整个行业深度与厚度,其总体科技长时间积累,其实力直追硅谷,并在一些领域实现了赶超。
另一方面,源于DeepSeek、百度持续十多年的布局、深研与进化。
早在十年前,梁文锋梁先生和三位同学创立了一家名为雅克比(Yakebi)的投资集团,试图将他们构建的算法交易模型变现。2019年,他就投资 2 亿元人民币成立了一个独立部门,以开发其名为 「Fire-Flyer 1」 的深度学习平台。
早在2011年,神经网络复兴之初,百度就看到了AGI的曙光。百度斥资4400万美元与谷歌、微软竞购人工智能之父辛顿旗下的一家AI公司。
虽然与辛顿失之交臂,过去十二年,李彦宏始终保持对AI技术的投入,百度一直延续压强式、马拉松式的研发投入,累计超过1000亿元,是全球创新投入最多的互联网公司之一。
百度已经成为国内唯一一家拥有全栈自研AI技术的公司,从硬件到软件。
百度自研万卡集群点亮,高效低成本背后,中国AI应用正加速繁荣。
国产万卡集群凭借自主可控的优势,让企业更低门槛地进行应用开发与产业创新,百度正为人工智能的发展注入新的活力。
DeepSeek「算力」与百度云万卡集群「算法」,如同弯道上两列极速列车,风驰电掣。
它们是中国AGI道路上的新引擎。
而未来,必将群星闪耀。




